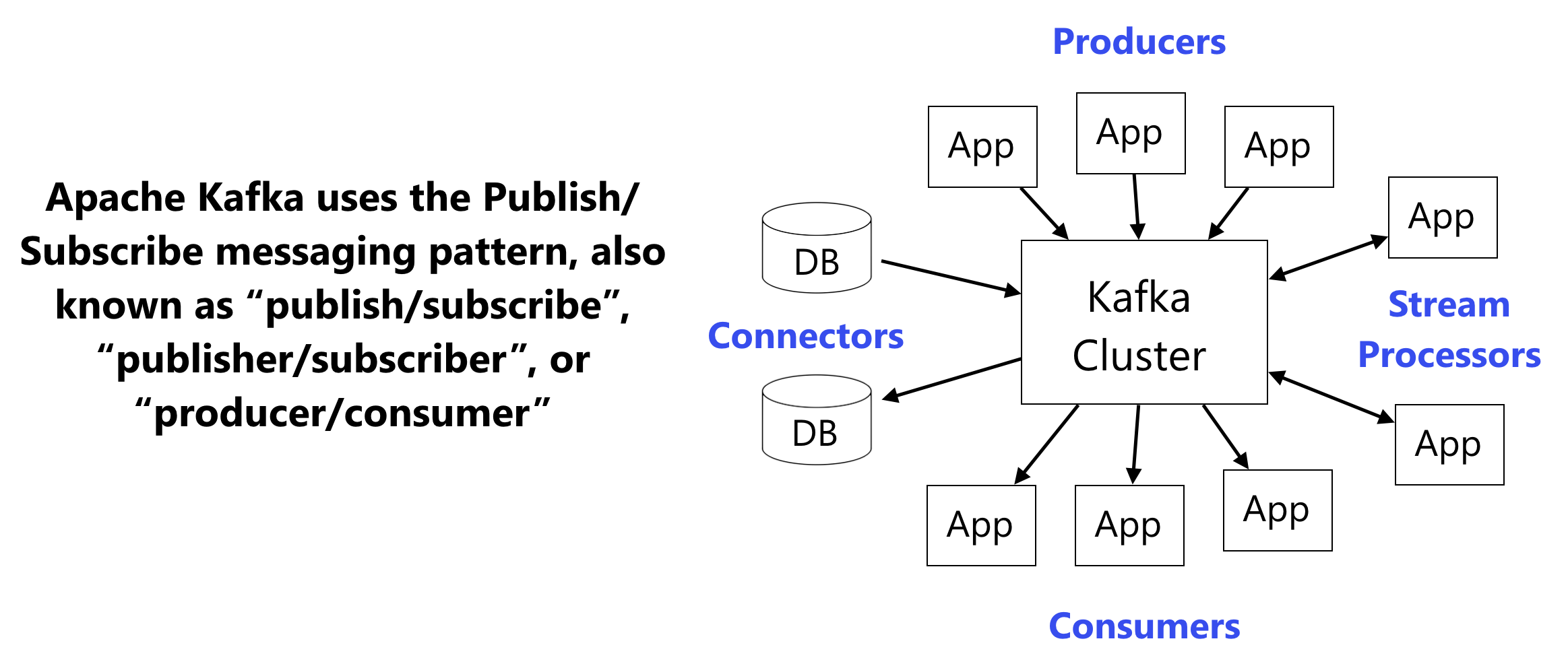
In a series of posts we are going to review different variances of platforms, frameworks, and libraries under the umbrella of Java. For this post, we are going to cover a basic view of Apache Kafka and why I feel that it is a better optimized platform than Apache Tomcat.
What is Apache Kafka? It is a streaming platform with three, key components:
- – Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system
- – Store streams of records in a fault-tolerant durable way
- – Process stream of records as they occur
BASICS
Kafka is used for real-time streams of data used to collect big data, to do real-time analysis or both. Kafka is used with in-memory microservices to provide durability, to feed events to cEP (complex event streaming systems), and IoT style automation systems.
Since Kafka is fast, scalable durable and fault tolerant publish/subscribe messaging system, it is used in cases where JMS, RabbitMQ and AmQP may not be considered due volume and responsiveness
APACHE KAFKA USE CASES
- – Stream processing
- – Website activity tracking
- – Metrics collections and monitoring
- – Log aggregations
- – Real-time analytics
- – Ingesting data into Hadoop
- – Replay messages
- – Error recovery
- – Guaranteed distributed commit log for in-memory computing
Also, Kafka has four, core APIs:
- – The Consumer API allows and application to subscribe to one or more topics and process the stream of records produced to them
- – The Streams API allows an application to act as a stream processor, consuming an input stream from on or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams
- – The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
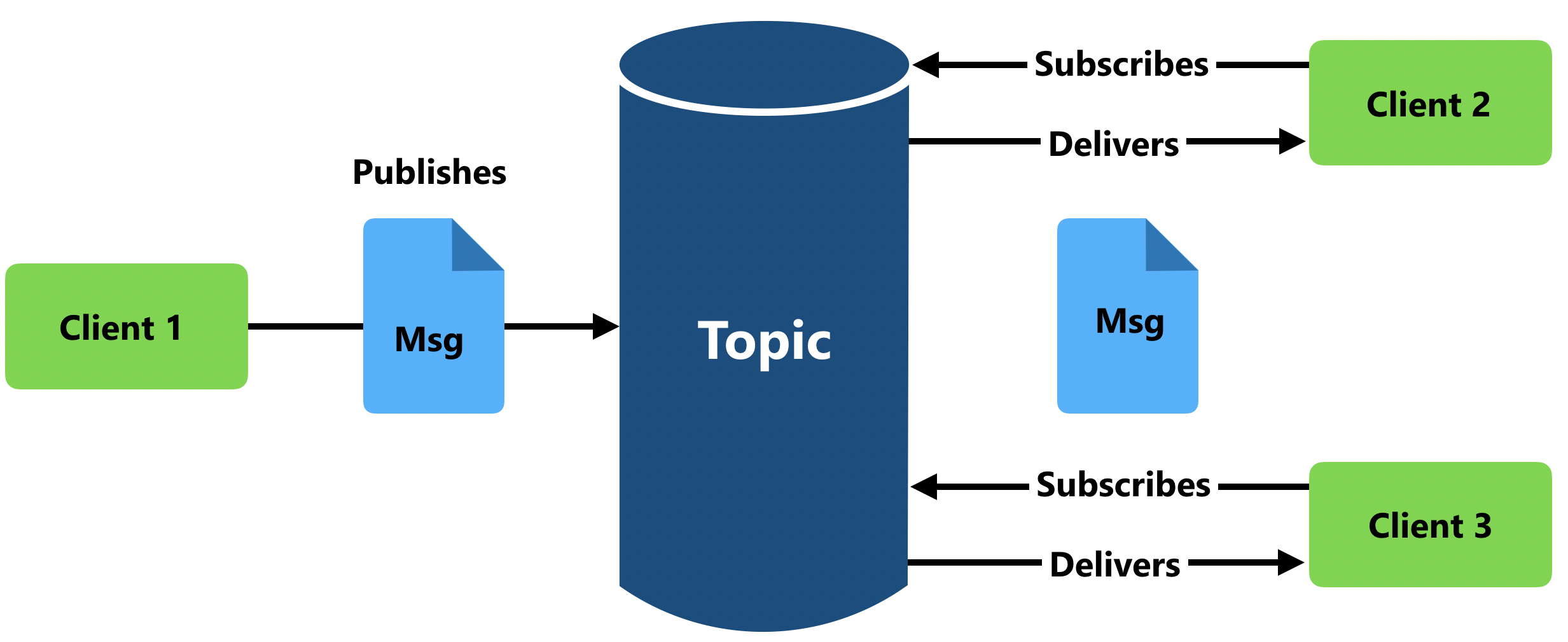
HOW IT WORKS:
The “publisher” generates data (a message) but it doesn’t have any reference to the subscriber, the message is not sent directly, instead of that the publisher can set the message in a certain “topic”. The receptor can subscribe it self in a certain topic and receive messages from this. Multiple receptors can be subscribed in a topic to get the information.
This diagram should provide for an easier understanding:
CHARACTERISTICS:
- Next Generation – used by Netflix, Microsoft, Banks, etc.
- High Performance – able to work with low latency because it comes from an OS kernel
- Distributed – Can be divided into several nodes inside a cluster
- Horizontal Scalable – Several nodes can be added in a few minutes
- Persistence – The messages are stored in a file system which can be replicated between the nodes in the cluster
- Fault Tolerant – All the nodes have a replica from other nodes. In the case that a node would fail, another would take its place
- Security – Support for SSL, SASL, GSSAPI. Can set encrypted connections for producers, consumers, brokers, & clients.
- Java Virtual Machine
- KSQL (similar to SQL) to work with streams
BASIC CONCEPTS
- Zookeeper – Software that provides a high performance coordination for distributed applications. This element should be the first one to start if the user wants a distributed coordination
- Broker – It’s a Kafka instance or server. Mediator in the communication for the message delivery
- Cluster – A group of Brokers
- Message – A data unit that works with Kafka, an example could be an array of bytes
- Schema – An optional structure applied on the messages. Some examples: JSON, XML, Apache Avro
- Topic – Category where the messages can classified in Kafka. A stream of messages with a name
- Partition – An ordered message sequence
- Offset – A unique identifier based in its place inside a partition. The consumer position in the topic or partition
HOW TO RUN APACHE KAFKA
The prerequisite is to install JRE
Step 1: Download Apache Kafka
To run Kafka, first we need to download the binaries from the site: https://kafka.apache.org/downloads
Step 2: Start the Server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.
For Windows:
binwindowszookeeper-server-start.bat config/zookeeper.properties
For Linux:
binzookeeper-server-start.sh config/zookeeper.properties
Now we start the server:
For windows:
binwindowskafka-server-start.bat config/server.properties
For Linux:
binkafka-server-start.sh config/server.properties
Step 3: Create a Topic
Creating a topic named “test” with a single partition and only one replica.
For Windows:
bin/windows/kafka-topics.bat –create –bootstrap-server localhost:9092 –replication-factor 1 –partitions 1 –topic test
For Linux:
bin/kafka-topics.sh –create –bootstrap-server localhost:9092 –replication-factor 1 –partitions 1 –topic test
To list the topics:
For Windows:
bin/windows/kafka-topics.bat –list –bootstrap-server localhost:9092
For Linux:
bin/kafka-topics.sh –list –bootstrap-server localhost:9092
Step 4: Sending the Messages
Run the producer and then type a few messages into the console to send to the server.
For Windows:
bin/windows/kafka-console-producer.bat –broker-list localhost:9092 –topic test
For Linux:
bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test
Step 5: Start a Consumer
Kafka also has a command line consumer that will dump out messages to standard output.
For Windows:
bin/windows/kafka-console-consumer.bat –bootstrap-server localhost:9092 –topic test –from-beginning
For Linux:
bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic test –from-beginning
CONCLUSION
Thanks for taking the time to review the basics of Apache Kafka, how it works and some simple examples of a message queue system. Be prepared for our next post, where we discuss how to use Kafka Streams to process data.
Stay Tuned!
REFERENCES
Víctor Madrid, Aprendiendo Apache Kafka, July 2019, from enmilocalfunciona.io
Víctor Madrid, Aprendiendo Apache Kafka Parte 2, July 2019, from enmilocalfunciona.io
Cloudurable, What is Kafka, July 2019, from cloudurable.com
Apache Kafka, Introduction, July 2019, from kafka.apache.com
Apache Kafka, Quick Start, July 2019, from kafka.apache.com