

Building an end-to-end AI chatbot with Python, Scrapy, Open AI [GPT-3.5] and custom training data
A complete guide to collecting real-world developer knowledge from Stack Overflow, preparing high-quality JSONL datasets, fine-tuning GPT-3.5 Turbo, and deploying a fully functional, AI-powered chatbot using Python, Scrapy, and OpenAI’s fine-tuning tools.
Real-world scenario usage:
In QA workflows, seconds matter. Whether you’re writing test assertions, debugging a flaky selector, or onboarding a new team member, access to focused, contextual knowledge can make or break velocity. This chatbot was fine-tuned using hundreds of Stack Overflow Q&A examples.
This same approach can be expanded far beyond dev/QA knowledge, enabling teams to instantly query internal documentation, surface business-specific insights, and accelerate decision-making with a domain-trained conversational assistant.
Not in Scope
- Python Cron Jobs / Scheduling This project does not cover setting up scheduled tasks or background job automation using cron, APScheduler, or similar Python scheduling libraries.
- Graphical User Interfaces (UI) The chatbot does not include a web-based or graphical UI (e.g., using Streamlit, Flask, or React). It operates purely through the command line or API interactions.
What you will need:
- Stackoverflow API Key
- Open AI API Key
- Tokens to fine-tune your models (Credit card)
Once the core logic is in place, the project is quick to build and execute.
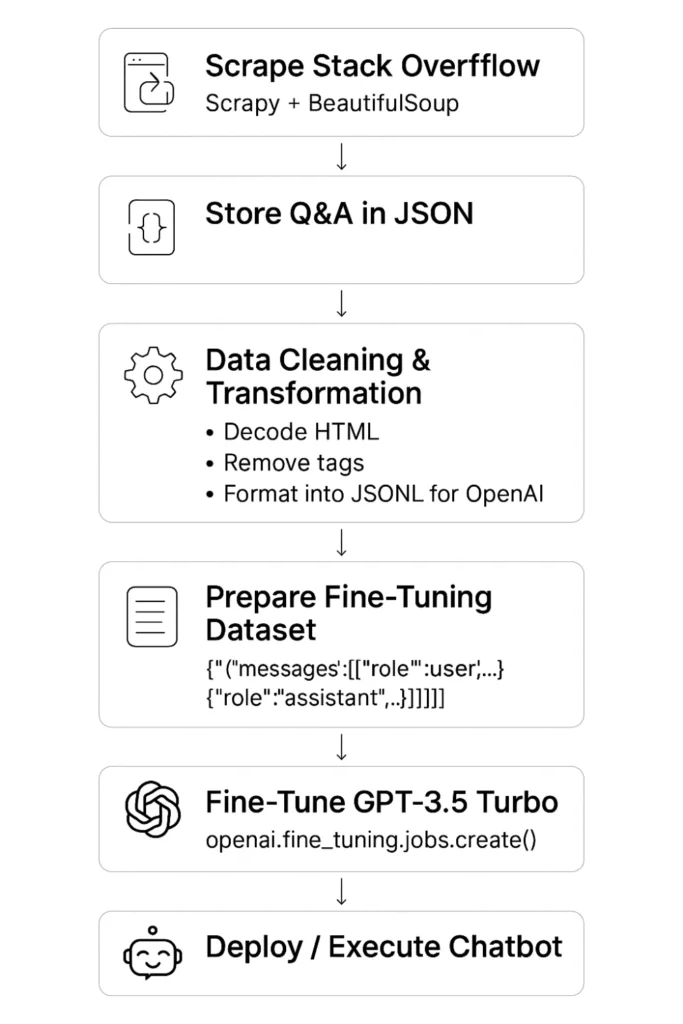
1. Scrape Stack Overflow
Tools: Scrapy, BeautifulSoup. Purpose: Extract real developer Q&A data for model training.
Using Python’s Scrapy and BeautifulSoup, we built a crawler that fetched high-voted questions and their accepted answers based on Python tags.
pip install scrapy scrapy startproject project_name scrapy startproject stackoverflowdemo
-- This will create a directory structure like this: stackoverflowdemo/ scrapy.cfg stackoverflowdemo/ __init__.py items.py middlewares.py pipelines.py settings.py spiders/ --- Add a file stackoverflow.py __init__.py
What is really important is the spider stackoverflow.py.
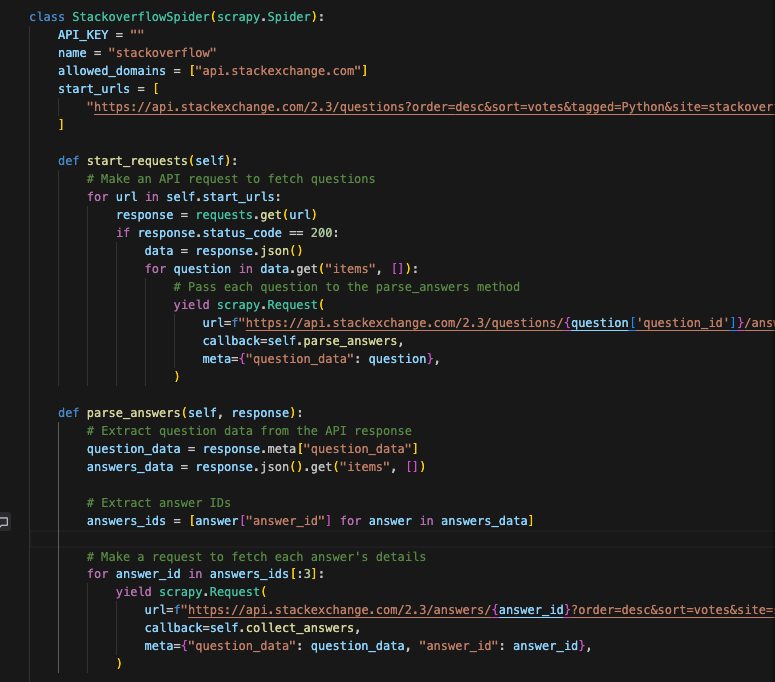
We first get all questions related to Python, and we limit the page size to 100.
start_urls = [ "https://api.stackexchange.com/2.3/questions?order=desc&sort=votes&tagged=Python&site=stackoverflow&key=rl_7MDaPq5dVss5TykzTyAY4soTi&pagesize=100" ]
In start_requests, we go through every question_id to obtain the answer_ids.
Url - question_id = 231767 https://api.stackexchange.com/2.3/questions/231767/answers?order=desc&sort=votes&site=stackoverflow&key=rl_7MDaPq5dVss5TykzTyAY4soTi
In parse_answers go iterate again to get the details of the answer (text). I’m limiting the cycle to only get the first 3 answers
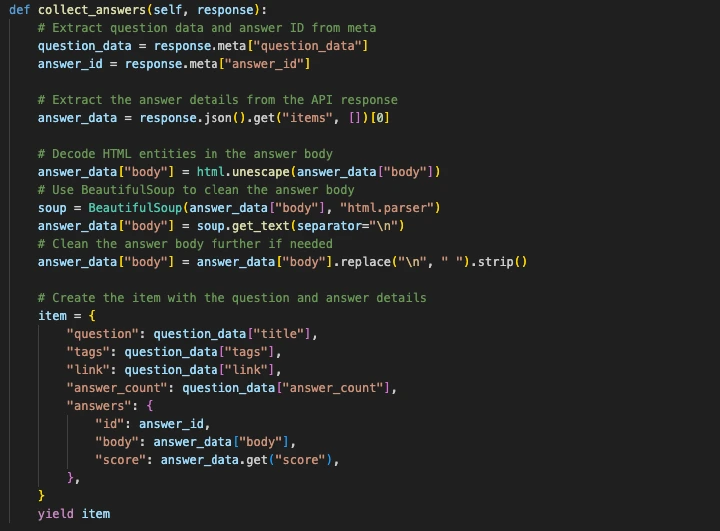
Finally, in collect_answers we “beautify” the body of the data and dump it into a JSON file.
2. Store Q&A in JSON Format
Format: .jsonl (JSON Lines) Why: OpenAI expects training data in newline-delimited JSON format.
Each Q&A pair is saved in structured JSON, keeping fields like question, tags, answer, and link.
In pipelines.py is where you will have the logic to make the JSON dump.

Your file should look like this format. (with around 300 lines of data).
{"question": "How do I split the definition of a long string over multiple lines?", "tags": ["python", "string", "multiline", "multilinestring"], "link": "https://stackoverflow.com/questions/10660435/how-do-i-split-the-definition-of-a-long-string-over-multiple-lines", "answer_count": 31, "answers": {"id": 24331604, "body": "Breaking lines by \\ works for me. Here is an example: longStr = \"This is a very long string \" \\ \"that I wrote to help somebody \" \\ \"who had a question about \" \\ \"writing long strings in Python\"", "score": 199}}
Some questions may include multiple answers (typically 2 or 3), which can lead to occasional repetition in the dataset. A potential improvement would be to group similar answers or select only the most relevant one for training.
3. Data Conversion & Transformation
In this step, we have to copy and paste the output file from the scraper to the Chatbot project. (I created a separate one, structure at the end of the article)
As you can see, there is an “input_file” and an “output_file”. For the model I’m using gpt-3.5-turbo-0125, this is the structure that I need.

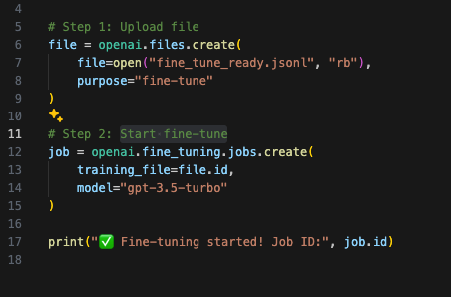
4. Fine-Tune GPT-3.5 Turbo
- Upload dataset
- Start fine-tune
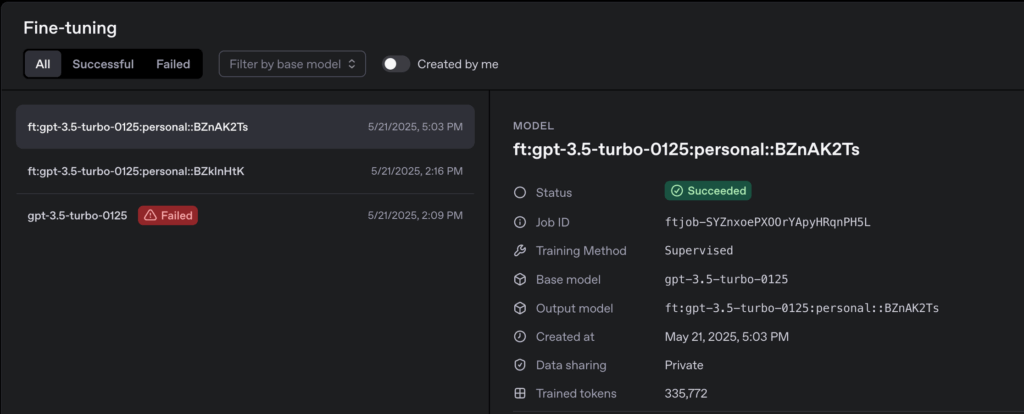
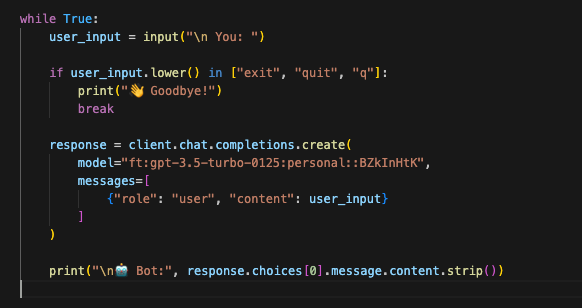
5. Deploy and Execute the Chatbot
Interface: Command Line or Python script
Final structure:
DEMO/ ├── Chatbot/ │ ├── chatbotmodel.py # Script for interacting with the fine-tuned chatbot model │ ├── fileconversion.py # Script to convert StackOverflow Q&A data into fine-tuning format │ ├── training.py # Script to upload data and start the fine-tuning process │ ├── requirements.txt # List of Python dependencies │ ├── output/ # Directory for storing output files │ │ ├── stackoverflow_qna.jsonl # Raw scraped Q&A data │ │ ├── fine_tune_ready.jsonl # Data formatted for fine-tuning │ │ └── cleaned_data.jsonl # Optional: Cleaned and processed data │ └── README.md # Documentation for the Chatbot module ├── stackoverflowdemo/ # Scrapy project directory for scraping StackOverflow data │ ├── scrapy.cfg # Scrapy configuration file │ ├── stackoverflowdemo/ # Main Scrapy project module │ │ ├── __init__.py # Marks this directory as a Python package │ │ ├── items.py # Define data structures for scraped items │ │ ├── middlewares.py # Scrapy middlewares (if needed) │ │ ├── pipelines.py # Define pipelines for processing scraped data │ │ ├── settings.py # Scrapy project settings │ │ └── spiders/ # Directory for Scrapy spiders │ │ ├── __init__.py # Marks this directory as a Python package │ │ └── stackoverflow.py # Spider for scraping StackOverflow data └── README.md # Documentation for the entire project
DEMO
Now, let’s address the concepts of:
- temperature: 0.2 – Makes the output focused and deterministic – (In this example, I chose to use 0.7)
- frequency_penalty: 0.5 -Reduces repeated words within the same response
- presence_penalty: 0.3 – Discourages repeating ideas/topics to make replies diverse
Notice the difference in the answers.







